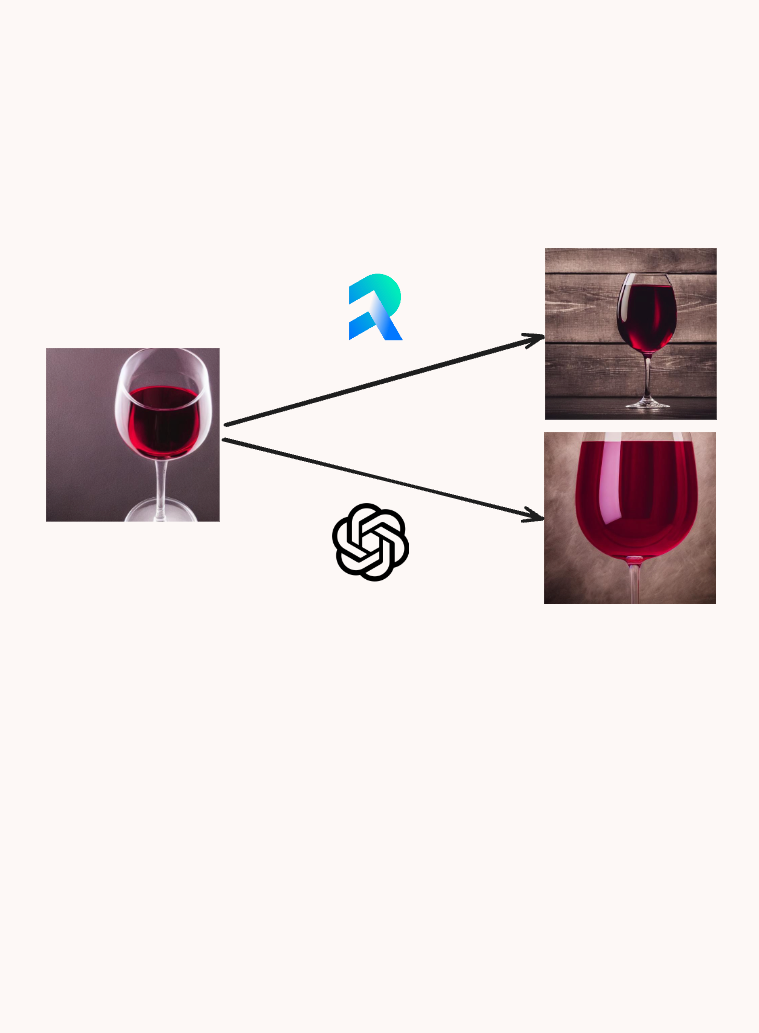

Gemini 2.5 Flash

Flux

GPT-4o

Vanilla Stable Diffusion

Stable Diffusion Fine-tuned (with GPT-4o feedback)

Stable Diffusion Fine-tuned (with Rapidata feedback)
Introduction
In the past few years, text-to-image models have evolved from DALL-E [7] to Stable Diffusion [8] to more recently Imagen 4 [9]. Early diffusion-based models struggled with simple tasks like consistently generating short texts on images or positioning and coloring objects correctly [3]. Modern multimodal models like GPT-4o are able to output images with long texts precisely and align better with prompts. But they can still struggle with unusual geometric shapes or panoramas [2].
One of the limitations of these models is the bias in the distribution of the data they are trained on. Despite being trained on hundreds of millions or even billions of images [1], their training sets can't capture all of the possible prompts one would wish to use for image generation.
A popular prompt that confuses text-to-image models is "completely full wine glass" [4]. Most of the images of wine glasses on the internet are not completely full, making it hard for models to generate the unexpected image. Even the most recent proprietary models with text-to-image capabilities like Flux or Gemini-2.5-Flash can't produce the desired image. The GPT-4o Image Generation [6] stands out from those. The generated glasses are almost full, sometimes even full to the brim. DALL-E 3 which was previously used for text-to-image generation in ChatGPT, however, was less successful at generating completely full wine glasses [4].
Note: the exact wording in the prompt did not affect the prompt-image alignment. We got similar results when we ran with the "filled to the brim" version of the promptFine-tuning the models for better alignment
What can we do to make models adhere to the wine glass prompt better? Finding completely full wine glass images and fine-tuning on them isn't a good option, since we are encountering the same problem that skews the generation towards not-full glasses: there are not many images of completely full wine glasses on the internet. And even if there were, this approach doesn't generalize to unrealistic images, like "a horse riding an astronaut" [3] that aren't available online.
If we can't get the right samples to train on, what can we do? The images a model generates for our prompt may look a bit different from how we want them to be. But still, some have more wine and adhere better, others don't. So we could try to measure how "good" the generated image is and reward the model for "good" images and punish for "bad" ones. In the best case, we would end up with only "good" images at the end of training. This is the main idea of reinforcement-learning-based methods in text-to-image models. One such method that we had the most success with is D3PO.
D3PO
The main idea of D3PO [10] is to replace the absolute measures of "good" and "bad" with preferences between pairs. To fine-tune a model, we don't need to assign a reward to each image anymore, we just want to know which image is better between the two generated ones.
The relative comparisons are easier to provide for humans. When you see a generated "completely full wine glass" by some model, it is hard to judge how good it is on a scale from 1 to 5. However, when you see a pair of images, you can judge which one is better. The pairwise approach is often used in RLHF training: both in the standard RL setting [14] and in LLM fine-tuning [13].
After training with this approach, we will get a model that aligns well with the preferences derived from the pairwise comparisons. But how do we know which image better satisfies the prompt? If one has more wine but looks more like a beer glass, is it better than a glass of wine with less wine? And who (or what) will give feedback on the pairs?
The answer to the first question are criteria — a list of requirements, that "good" images should satisfy. See the actual list and preference guidelines in the Criteria and Validation section.
To answer the second question: we will try both human and artificial judges.
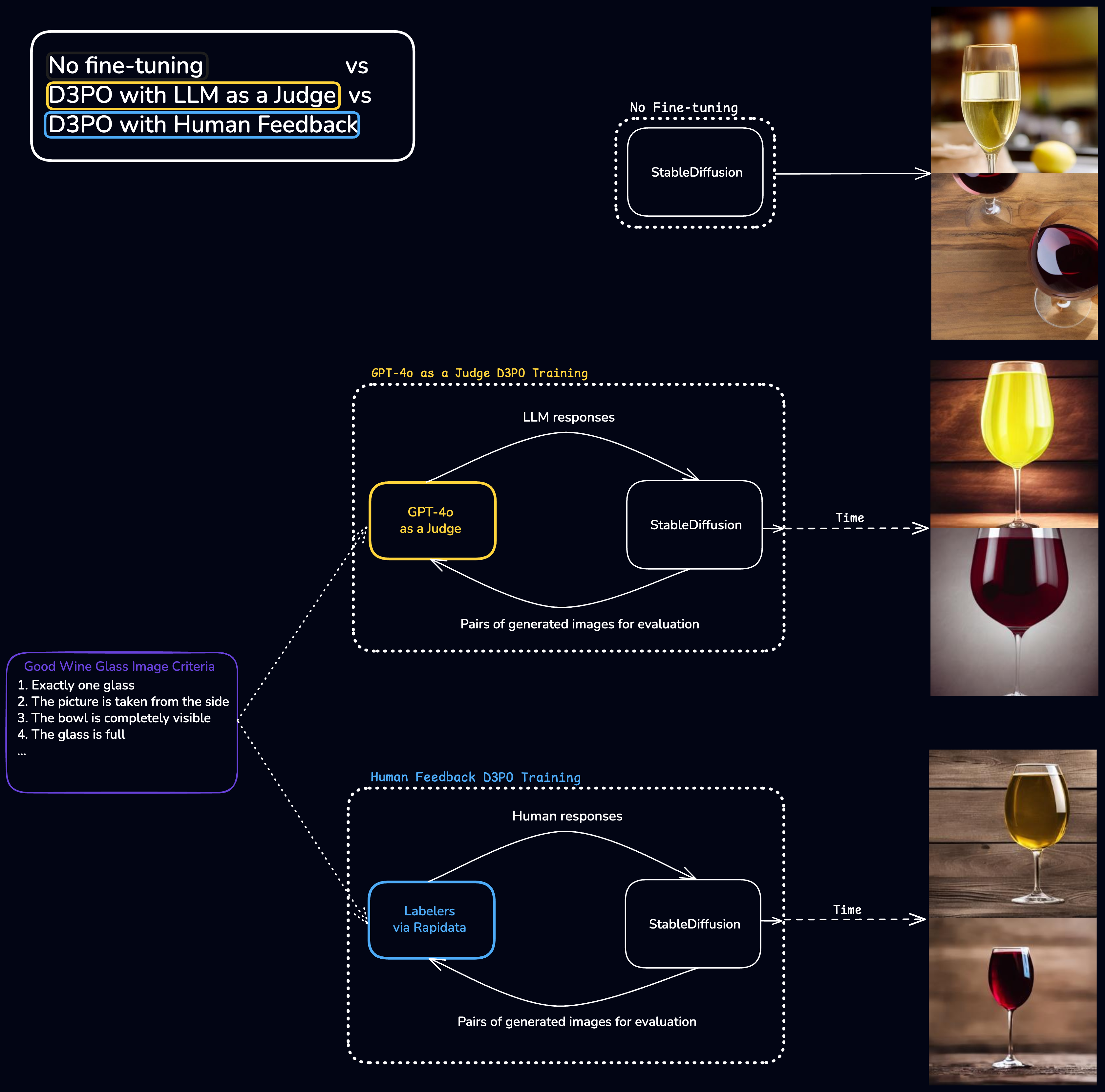
D3PO training illustration with Rapidata and GPT-4o feedback.
GPT-4o as a Judge
Modern multimodal foundation models are respectable generalists [11]. They can solve vision tasks, different from those they were trained on. Among them, GPT-4o is one of the strongest [11]. So we use it as the first judge in our training pipeline.
To instruct the model about the criteria, we add them and 7 example pairs as few-shot data to the prompt. We also prompt the model to provide a brief explanation of the choice, as in the validation examples. This approach is similar to Chain-of-Thought which was shown to improve LLMs' performance [12].
Rapidata Feedback
A natural way to know which image looks better is to ask a human. That is exactly what we do with our second judge — we ask people which image they prefer with Rapidata.
To train annotators to label according to the criteria, we make a validation set with the 7 validation pairs. Crucially, both GPT-4o and Rapidata labelers receive the same validation pairs, giving the same information to both judges. We only present real labeling tasks to people who have achieved a certain level of mastery on the validation set.
Rapidata vs GPT-4o
Image Quality
After we trained Stable Diffusion with both types of feedback, we evaluated the resulting models to compare the effects of training with both judges.
Here is a collage of samples generated at the end of training. From it we see that the Rapidata-feedback model generations look more natural.

Rapidata

GPT-4o
We log all checkpoints to evaluate how the models change with more feedback and training. Here is how the images changed:

Evolution of generated images throughout training for Rapidata and GPT-4o feedback. The images are generated from the same initial noise.
We notice that with training the generated images are starting to look more and more like "completely full wine glass". Images generated with GPT-4o, however, tend to look less realistic and, more importantly, they begin to violate one of the criteria which instructs us to prefer wine glasses with a completely visible bowl. It turns out that GPT-4o struggles with this criterion not only due to our specific preference task and prompting, but because the model can't determine whether the bowl is within the image at all. See the GPT-4o cannot determine whether the glass is within the image section for analysis.
For a robust comparison of both training regimes, we benchmark their checkpoints with CrowdEval. CrowdEval uses metrics introduced by [15] for pairwise comparisons. Our evaluation uses coherence and preference metrics. The first one asks which image has more glitches and is more likely to be AI generated. The second one asks a labeler which image they prefer.
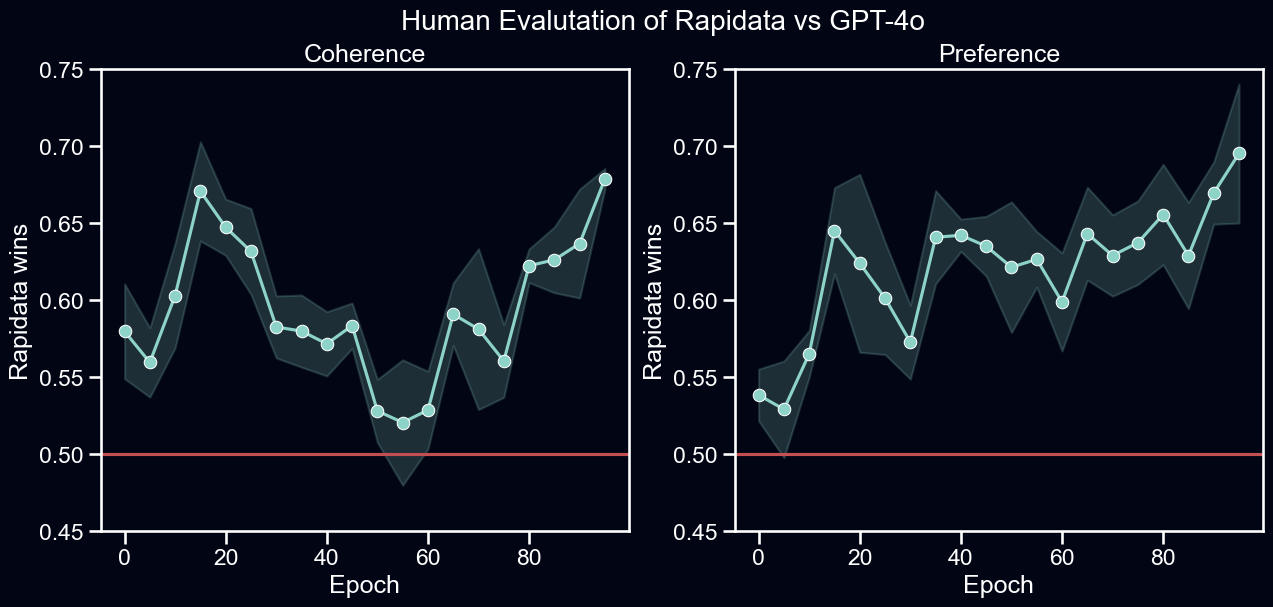
Comparing model checkpoints from training with Rapidata and GPT-4o using CrowdEval. The higher the metric, the better Rapidata performs relative to GPT-4o. At each evaluated timestamp, 32 pairs of images are generated and 8 human responses are collected per pair. Results are averaged over 5 CrowdEval runs, one standard deviation is shaded. Checkpoints using Rapidata responses outperform those of GPT-4o on coherence and preference across all epochs.
Both metrics are statistically significantly above 0.5 throughout training, indicating that the Rapidata-feedback model is preferred by humans. After epoch 80, both metrics increase to the 0.6-0.7 range. This rise in relative Rapidata-feedback model performance is consistent with our observations on generated image dynamics. Closer to the end of training, images generated with GPT-4o feedback tend to be less realistic and the bowl starts extending beyond the image borders.
If you want to learn more about what Rapidata human annotation is capable of in vision tasks, see our blog about image labeling with human feedback.
Training
We have the same training setup for both types of feedback. Stable Diffusion was fine-tuned on 8 L4 GPUs for 100 epochs. In each epoch, each GPU generates 16 image pairs. In total, there are 16 (image pairs) × 8 (GPUs) × 100 (epochs) = 12'800 image pairs for fine-tuning. The Rapidata feedback gathers 2 responses per data point, so ~25'600 human responses in total.
Costs
We used ~100 USD worth of Rapidata API and we spent ~130 USD on GPT-4o API. A significant part of the GPT-4o API usage comes from the few shot examples provided to the model before the actual query. We ablated few-shot prompts to see whether we could spend less on the API. It turns out that we can't; the judge becomes inconsistent and the model collapses. See No Criteria Runs.
Conclusion
We fine-tuned Stable Diffusion with RL using two different types of feedback. Both improved over the baseline but in the end of training GPT-4o-feedback model generates worse images than Rapidata-feedback one. The glasses look less natural and violate the border of the image. This suggests that quality human feedback can deliver better results for tasks that are intuitive to people and out of training distribution for models.
Modern multimodal foundation models can perform vision tasks reasonably well [11] but there are still gaps in their capabilities. The worst thing about these gaps is that we often don't know what they are before we find them. In our case, one gap is bowl detection. A seemingly slight issue led to a drift in the generation model, which wrongfully started generating images of wine glasses going beyond the borders of the image.
We, as humans, have common sense, and, given the right instructions, can express it clearly in our responses. These responses will transfer our preferences to a model which will learn to generate images that we want. That is why by the end of training we have a better-performing fine-tuned Stable Diffusion.
References
[1] Text-to-image training dataset sizes, 2022 https://s10251.pcdn.co/pdf/2022-Alan-D-Thompson-AI-Text-to-Image-Bubbles-Rev-1.pdf
[2] An Empirical Study of GPT-4o Image Generation Capabilities https://arxiv.org/pdf/2504.05979
[3] Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding https://arxiv.org/pdf/2205.11487
[4] Reddit post about generating full wine glasses https://www.reddit.com/r/ChatGPT/comments/1gas25l/your_mission_should_you_choose_to_accept_it_is_to/
[5] Reddit post about successfully generating a wine glass filled with beer https://www.reddit.com/r/ChatGPT/comments/1ixgfc0/guys_i_did_it_nobody_ever_said_the_wine_glas_must/
[6] Introducing 4o Image Generation https://openai.com/index/introducing-4o-image-generation/
[7] Zero-Shot Text-to-Image Generation https://arxiv.org/pdf/2102.12092
[8] High-Resolution Image Synthesis with Latent Diffusion Models https://arxiv.org/pdf/2112.10752
[9] Imagen 4 is now available in the Gemini API and Google AI Studio https://developers.googleblog.com/en/imagen-4-now-available-in-the-gemini-api-and-google-ai-studio/
[10] Using Human Feedback to Fine-tune Diffusion Models without Any Reward Model https://arxiv.org/pdf/2311.13231
[11] How Well Does GPT-4o Understand Vision? Evaluating Multimodal Foundation Models on Standard Computer Vision Tasks https://arxiv.org/abs/2507.01955
[12] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models https://arxiv.org/pdf/2201.11903
[13] Training language models to follow instructions with human feedback https://arxiv.org/pdf/2203.02155
[14] Deep Reinforcement Learning from Human Preferences https://arxiv.org/pdf/1706.03741
[15] Rich Human Feedback for Text-to-Image Generation https://arxiv.org/pdf/2312.10240
Complementary Sections
Criteria and Validation
To exactly know which images are better, we make a list of criteria that we supply to the judge that uses it to determine which images are better. The list is the following:
| Priority | Instruction |
|---|---|
| 1 | Exactly one glass |
| 2 | Picture from the side |
| 3 | Wine glass has proper stem and the bowl is completely visible |
| 4 | The glass is full |
| 5 | The liquid inside is wine |
Priority determines how important each instruction is. An image which has more top-priority instructions satisfied wins. For example, if two images satisfy instructions 1, 2, 3 and 1, 2, 4, 5 respectively, the first one would win because both of them satisfy 1, 2, but the second one doesn't satisfy 3. We composed this list empirically based on what was mostly wrong with the Stable Diffusion generations before fine-tuning. The fullness of the glass is only on the fourth position because we noticed that the images generated by vanilla Stable Diffusion tend to be deformed and not follow the first 3 seemingly obvious criteria. To better instruct the judge on the criteria, we additionally generate 7 pairs of validation samples.
GPT-4o cannot determine whether the glass is within the image
Consider this example:

First image in the image pair

Second image in the image pair
There is a few-shot example showing that the glasses completely within the image should be preferred. Nevertheless, we found many examples similar to the one above where criterion #3 isn't evaluated correctly.
We claim that the problem is not in the complex criteria, but specifically in determining whether the glass is within the image. To prove that, we prompt GPT-4o with the image and ask whether the bowl is within the image, we get an incorrect response that the bowl is completely within the image. Thinking models like o4-mini-high and o3, however, answer the question correctly. We also note that the claim that both of the glasses are full is not correct.
No Criteria Runs
We find the criteria to be a crucial part of our approach, as otherwise the judge might be inconsistent. We ran an experiment where we completely omitted the criteria and only asked which image better aligns with the prompt. The models collapsed in both cases, no matter the judge.
DDPO
The model generated completely full wine glasses, but the liquid inside looked more like beer. It seems easier to make models generate glasses filled to the brim with beer than with wine [5].
